
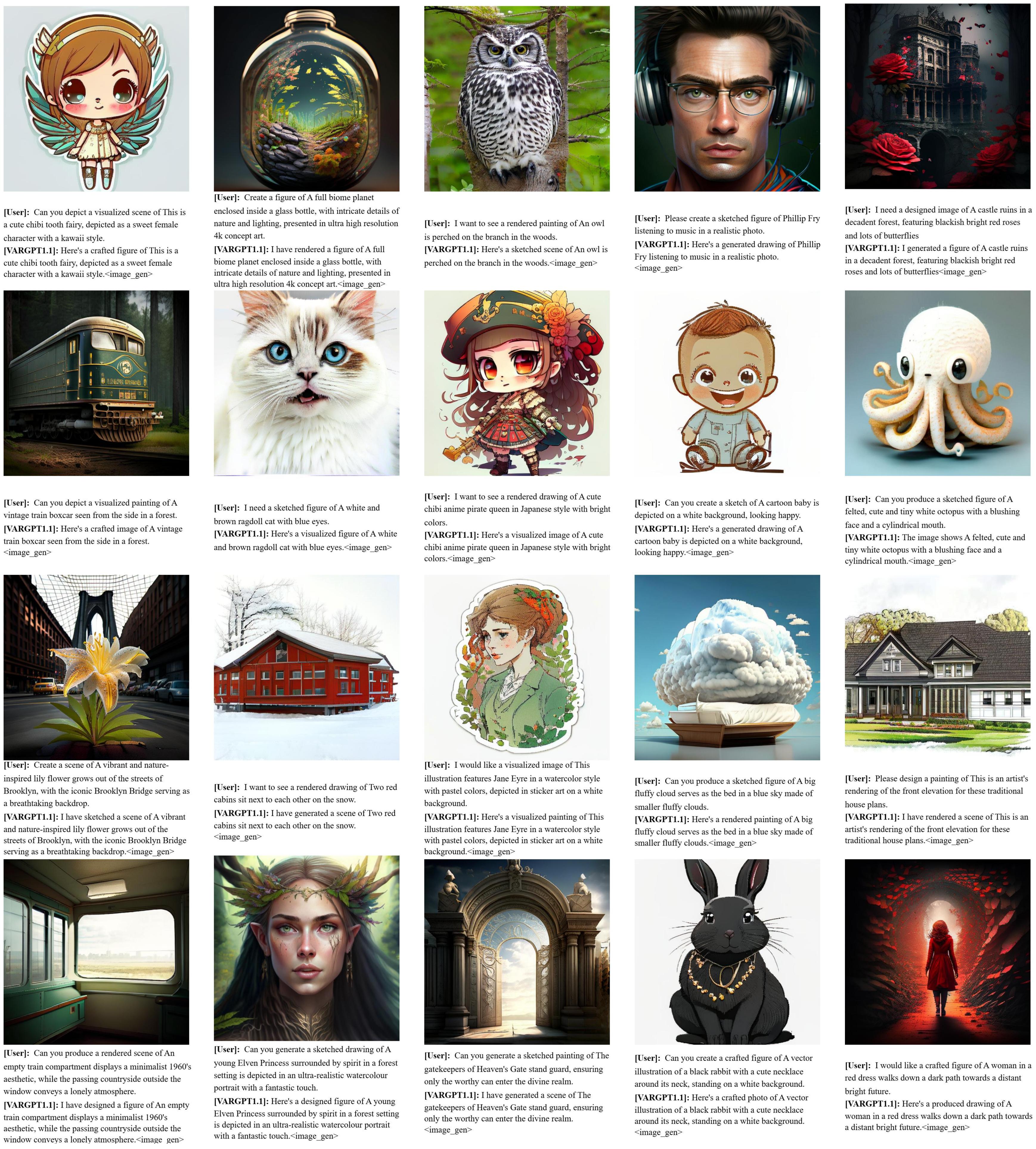
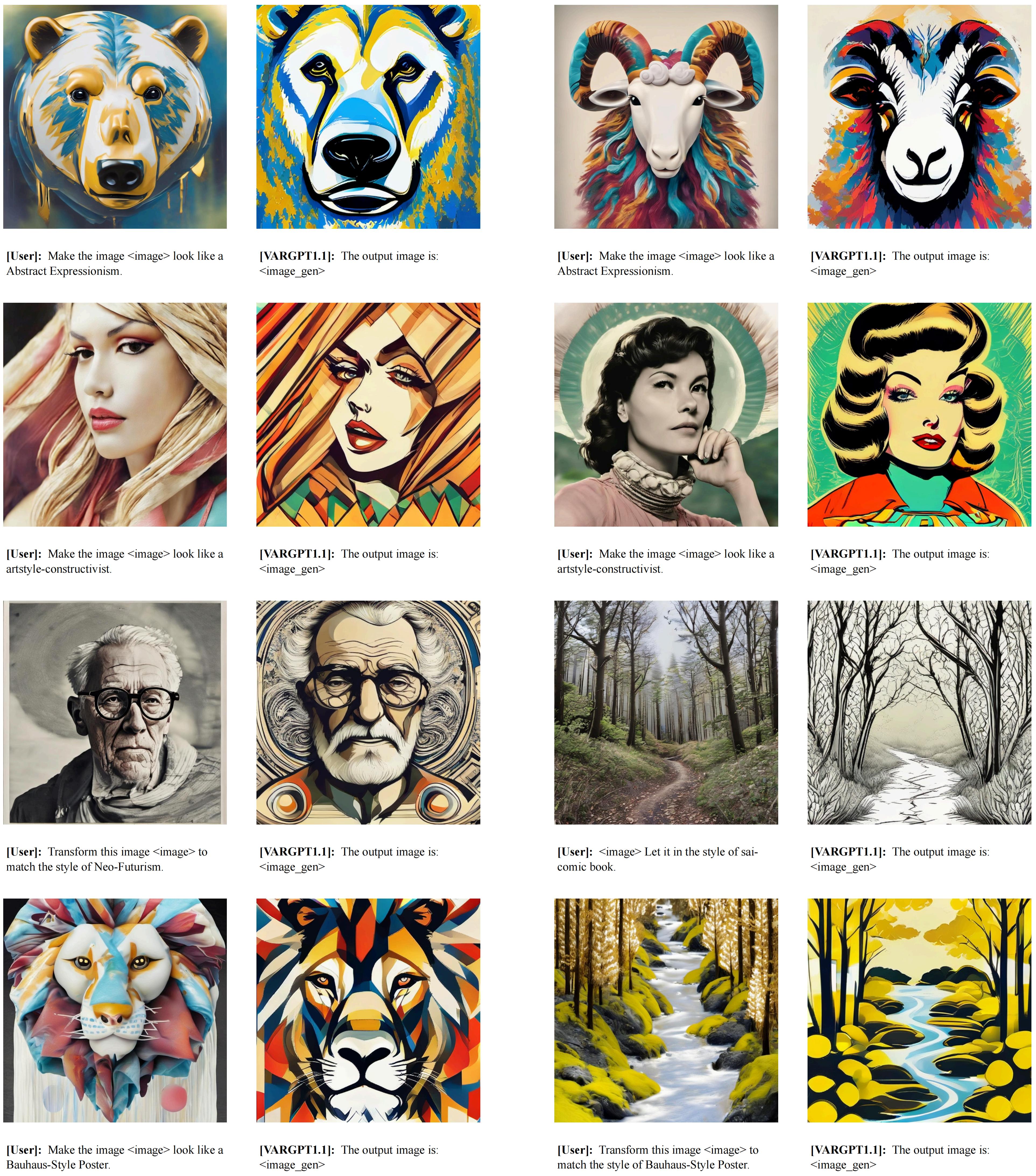
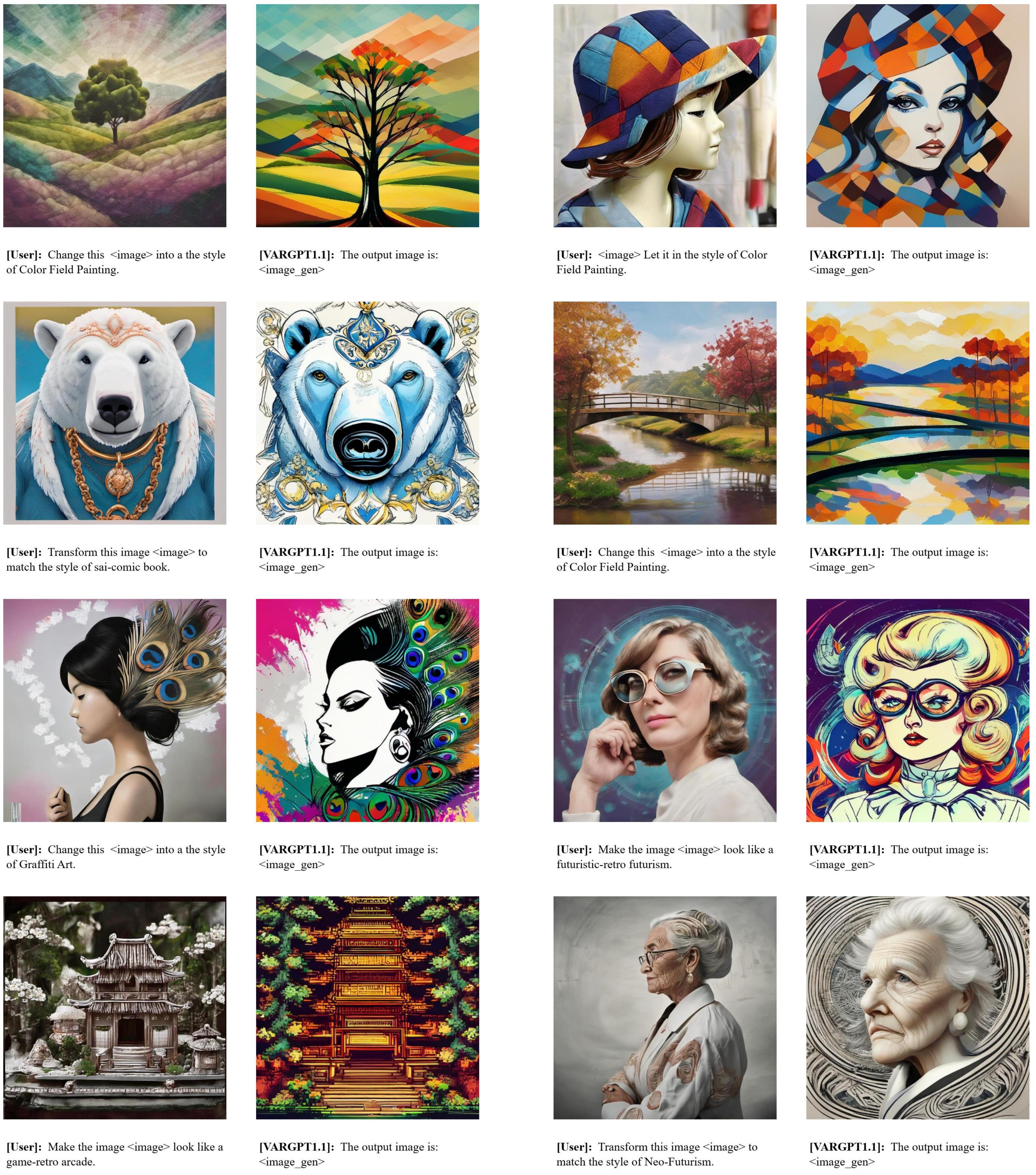
In this work, we present VARGPT-v1.1, an advanced unified visual autoregressive model that builds upon our previous framework VARGPT. The model preserves the dual paradigm of next-token prediction for visual understanding and next-scale generation for image synthesis. Specifically, VARGPT-v1.1 integrates: (1) a novel training strategy combining iterative visual instruction tuning with reinforcement learning through Direct Preference Optimization (DPO), (2) an expanded training corpus containing 8.3M visual-generative instruction pairs, (3) an upgraded language backbone using Qwen2, (4) enhanced image generation resolution, and (5) emergent image editing capabilities without architectural modifications. These advancements enable VARGPT-v1.1 to achieve state-of-the-art performance in multimodal understanding and text-to-image instruction following tasks, demonstrating significant improvements in both comprehension and generation metrics. Notably, through visual instruction tuning, the model acquires image editing functionality while maintaining architectural consistency with its predecessor, revealing the potential for unified visual understanding, generation, and editing. Our findings suggest that well-designed unified visual autoregressive models can effectively adopt flexible training strategies from large language models (LLMs), exhibiting promising scalability.
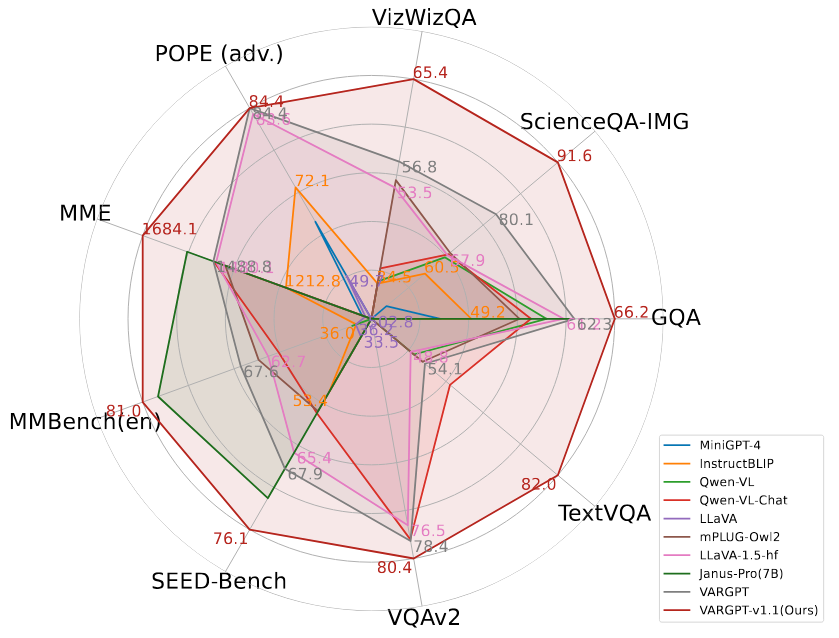
A comparative analysis of various MLLMs across multiple visual comprehension benchmarks is presented. The remaining metrics are derived from standard visual question-answering benchmarks and multi-modal comprehension benchmarks. Notably, our VARGPT-v1.1 model demonstrates significant superiority over the compared baselines across all comprehension benchmarks.
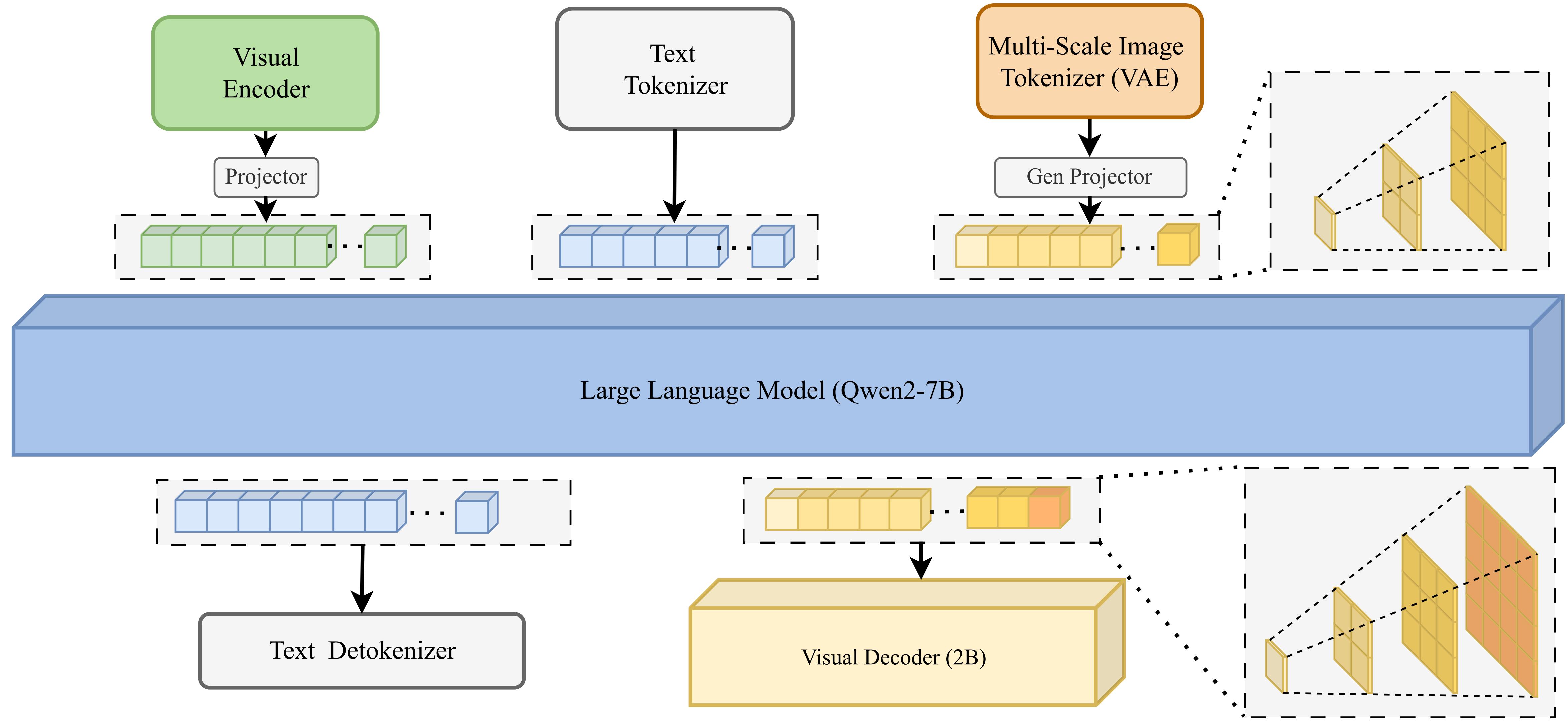
The illustration of the proposed VARGPT-v1.1 framework similar to VARGPT, which consists of (1) a LLM (Qwen2-7B- Instruct), visual encoder and a understanding projector for visual understanding; (2) a visual decoder and dual generation projectors for visual generation. VARGPT-v1.1 employs the causal attention in the LLM backbone, while utilizing block causal attention in the visual decoder.
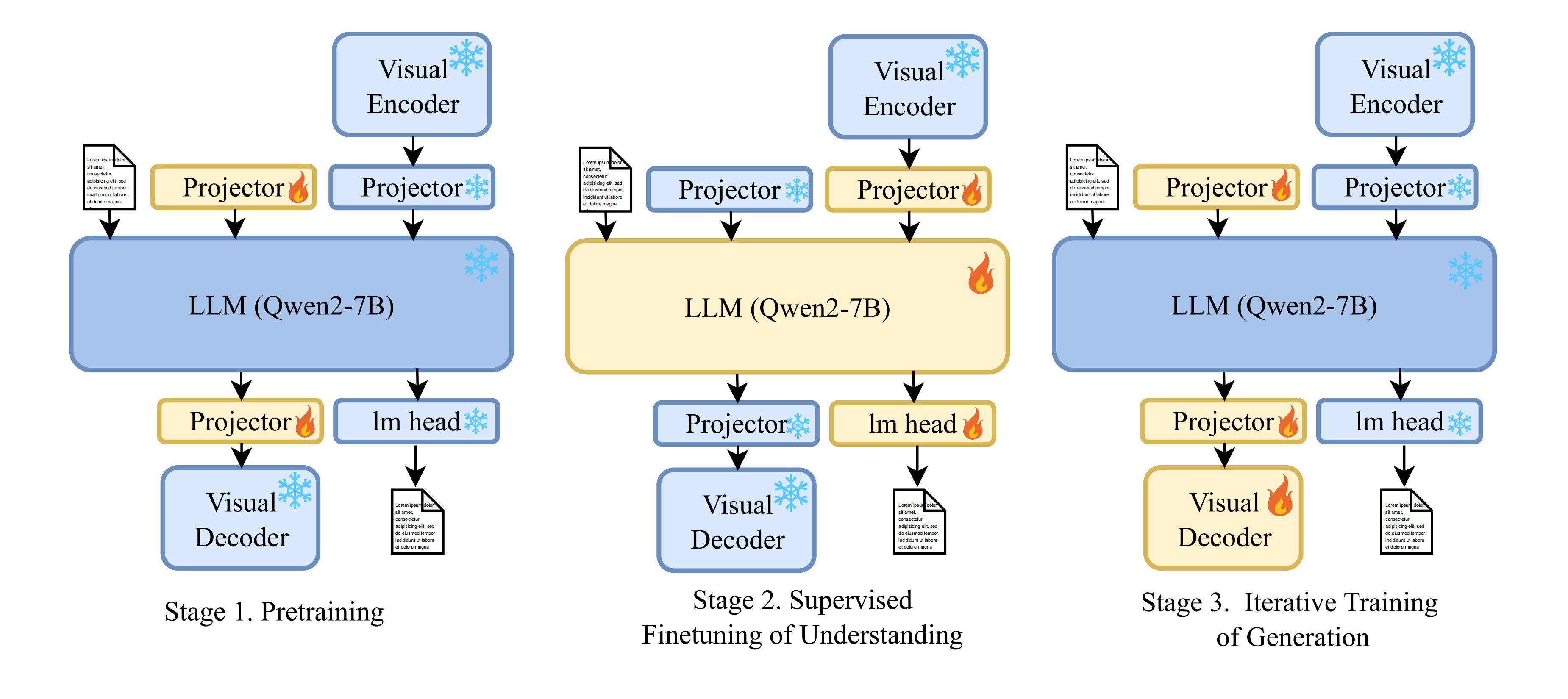
The three training stages of the VARGPT, including stage-1 pretraining, stage-2 visual instruction tuning and stage-3 iterative training.

The proposed iterative training strategy for the third stage gradually increases the resolution of the image, while using instruction finetuning and reinforcement learning iterative training. Finally, we use the instruction-follow dataset for image editing to stimulate the model’s visual editing ability.
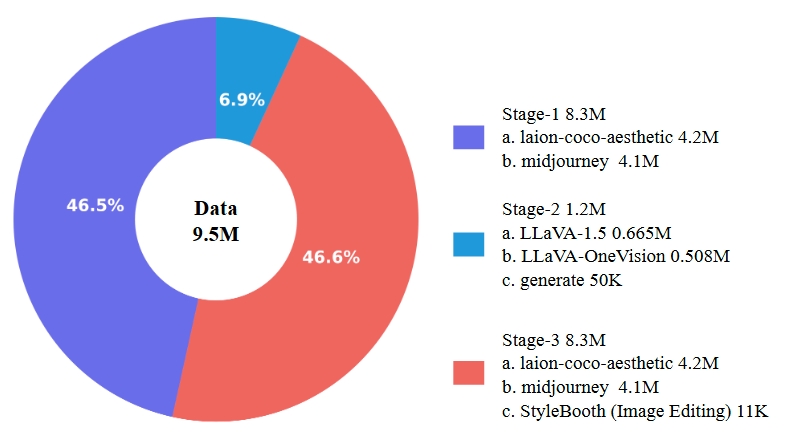
We present the data distribution we construct and collect, encompassing the proportional breakdown of data across the three training stages. Our composite dataset for stage-2 training is derived from LLaVA-1.5, LLaVA-OneVision.
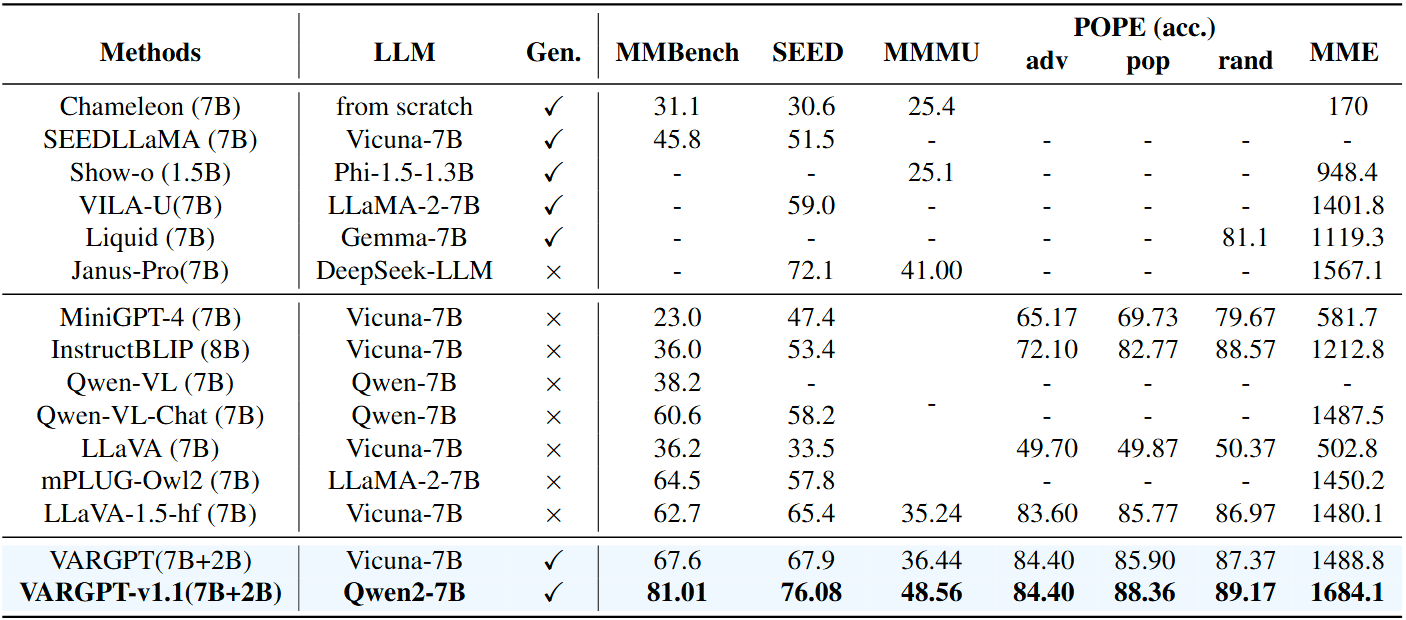
Zero-shot multi-modal evaluation on multi-modal benchmarks including MMMU, MME, MMBench, SEEDBench, and POPE (including different settings random, popular and adversarial ). The overall scores are reported for evaluation and we report test results for MMBench. Gen represents whether the method supports image generation capability. VARGPT-v1.1 achieves the best overall performance.
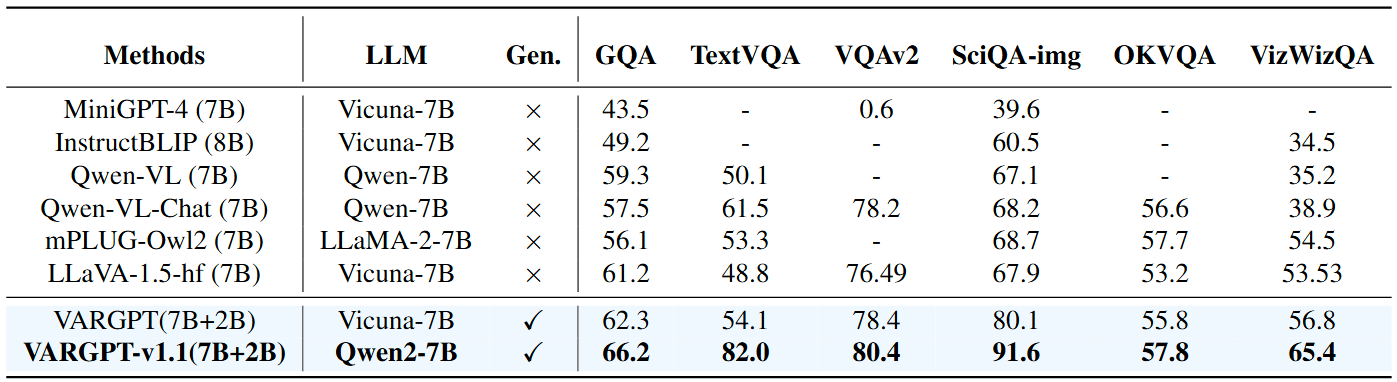
Performance comparison on visual question answering tasks. We gray out the model has trained on the dataset. Gen represents whether the method supports image generation capability.
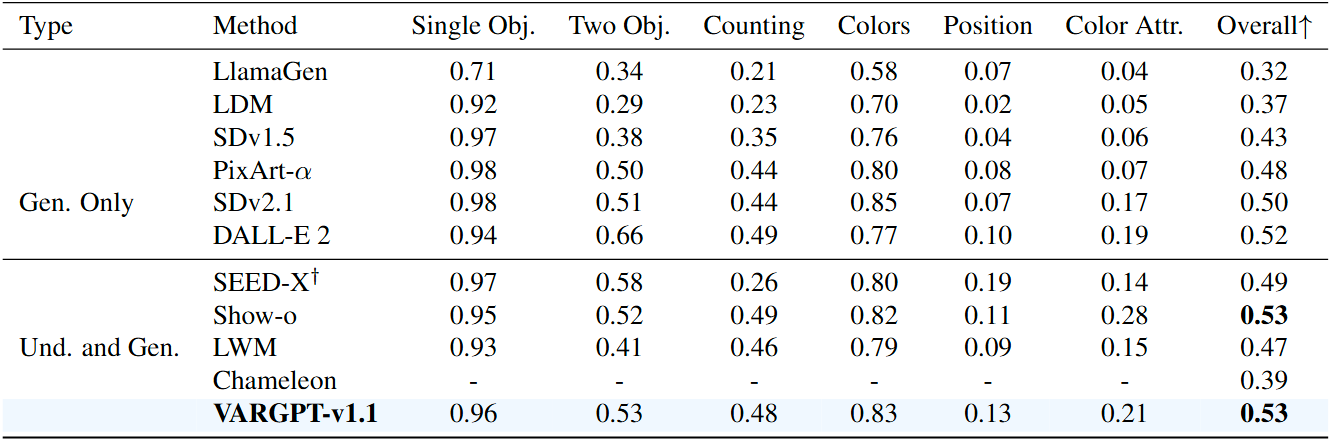
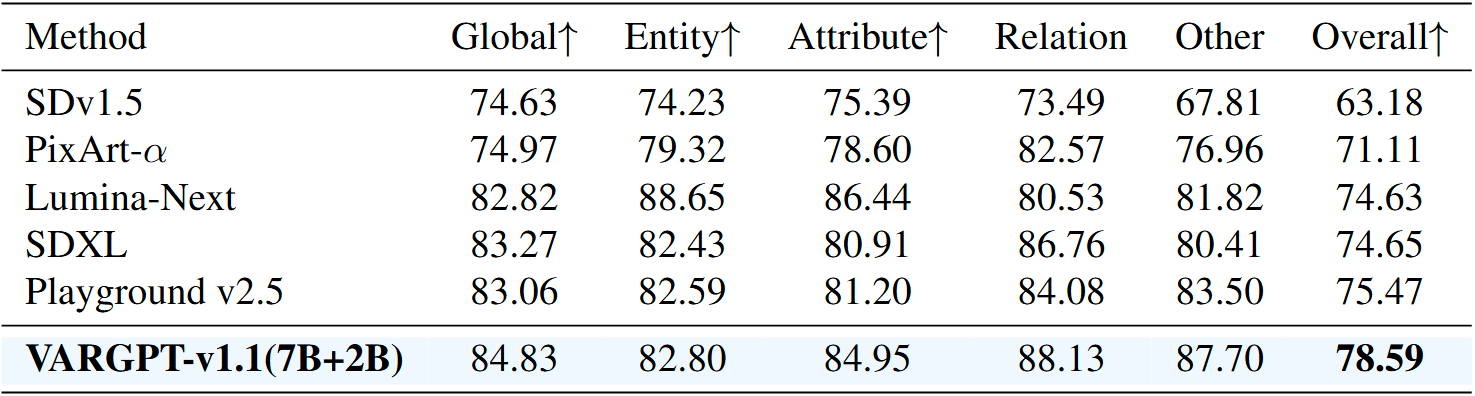


@misc{zhuang2025vargptunifiedunderstandinggeneration,
title={VARGPT: Unified Understanding and Generation in a Visual Autoregressive Multimodal Large Language Model},
author={Xianwei Zhuang and Yuxin Xie and Yufan Deng and Liming Liang and Jinghan Ru and Yuguo Yin and Yuexian Zou},
year={2025},
eprint={2501.12327},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.12327},
}